[궁금한 화요일] 빅데이터의 2년 전 경고 “메르스, 아시아가 가장 위험”
중앙일보 2015.6.1
‘감염병 확산 방정식’ IT가 푼다
미국, 인구·교통 정보 활용한 감염병 예측 프로그램 개발
메르스는 중동 오가는 항공편 분석 … “아시아 발병 가능성 66%·유럽 21%”

전병율(연세대 보건대학원 교수) 전 질병관리본부장은 2009년 신종플루가 퍼졌을 때 겪은 경험을 이렇게 요약했다. 그는 당시 질병관리본부 전염병대응센터장을 맡았다. 그때 경험을 토대로 현재 중동호흡기증후군(MERS·메르스)과 싸우는 후배들에게 조언을 한 것이다. <중앙일보 6월 8일자 8면>처음 감염병이 퍼질 땐 사람들이 너무 놀라지 않도록 적절한 수준에서 경고를 해야 한다. 반면 막판에는 가능한 모든 의학적 수단을 동원해 질병과 싸워야 한다. 한데 그 중간에서 수학은 어떤 역할을 한다는 걸까.
보건당국의 역학조사는 환자 접촉자를 찾는 데 초점이 맞춰져 있다. 쉽게 말해 누구에게 병을 옮아 누구에게 옮겼는지 감염자의 ‘뒤를 쫓는’ 방식이다. 대상자 전체를 실시간 확인하지 못한다면 항상 바이러스보다 한발 늦을 수밖에 없다. 만일 병이 퍼지기 쉬운 곳, 감염 가능성이 더 높은 사람들을 미리 가려낼 수 있다면 얘기가 달라진다. 물론 공상과학(SF) 영화에서처럼 대상자를 한 명 한 명 족집게처럼 집어내는 건 불가능하다. 하지만 상대적으로 확률이 높은 대상만 추려내도 방역의 효율을 높일 수 있다. 그런 확률을 계산하는 데 수학이 핵심적인 역할을 한다는 게 전문가들 얘기다.
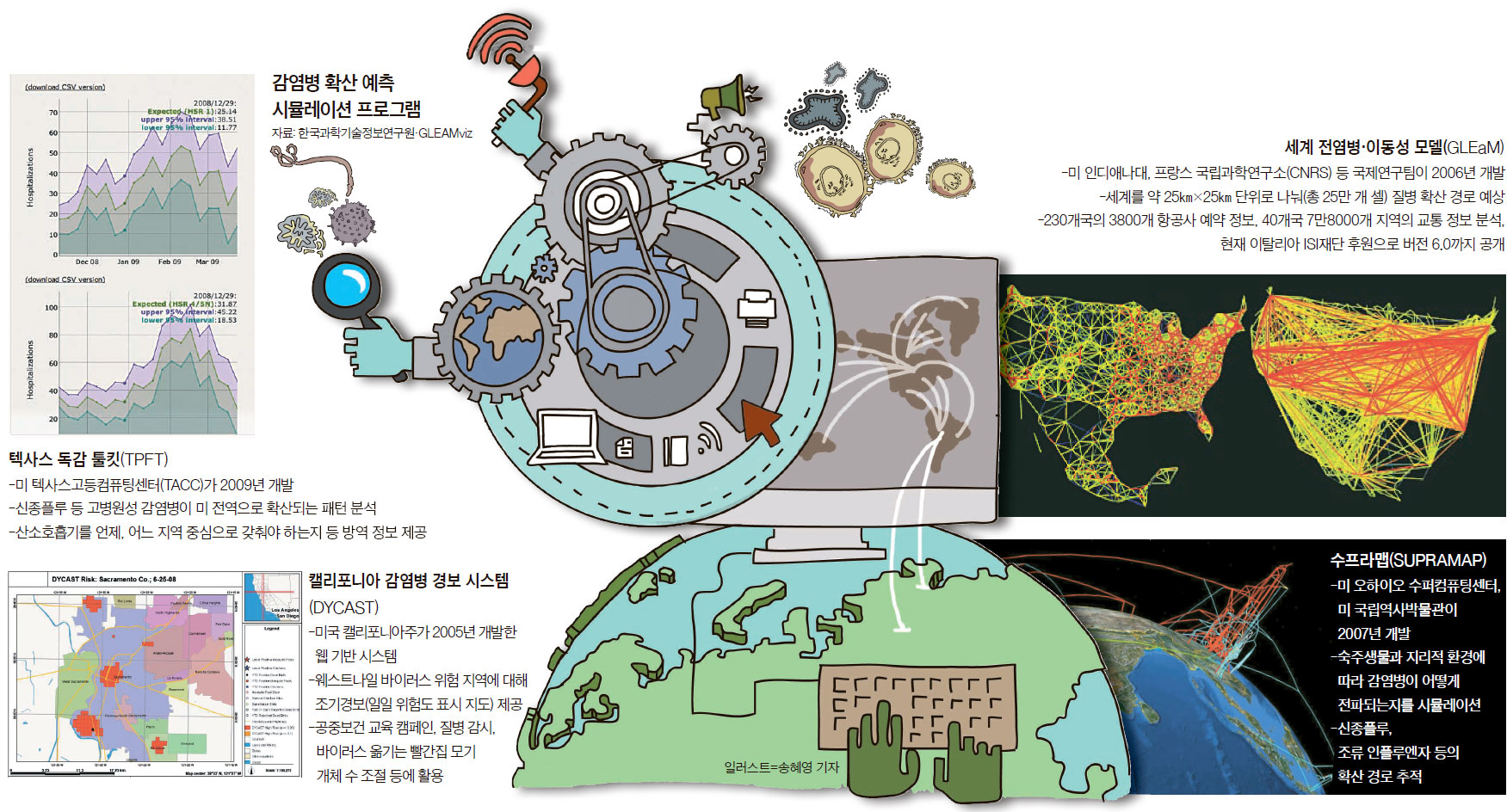
실제로 미국·유럽 등은 2002년 중증급성호흡기증후군(SARS·사스), 2009년 신종플루 사태 등을 겪으며 이런 연구를 시작했다. 방법은 이렇다. 먼저 각 질병의 전파 과정을 방정식 모델로 만든다. 감염 가능성이 있는 사람, 잠복기에 있는 사람, 감염자, 완치자를 변수로 놓고, 다양한 접촉 조건에서 병이 퍼질 가능성을 따진다. 여기에 실제 사람들의 인구 데이터, 이동 정보를 결합해 한 지역에서 발생한 감염병이 언제, 어디로, 얼마나 퍼질까를 예측한다. 2006년 미국 IBM연구소가 개발한 ‘시공간 전염병 모델러(Spatio Temporal Epidemiological Modeler, STEM), 같은 해 미 인디애나대와 프랑스 국립과학연구소(CNRS) 등 국제공동연구팀이 만든 ‘세계 전염병·이동성 모델(GLobal Epidemic and Mobility model, GLEaM)’ 등이 이렇게 만들어진 시뮬레이션 프로그램이다.
STEM은 미국 각 주 단위의 인구 정보, 출생률, 사망률 등을 기초로 정보를 업데이트한다. 여기에 각지의 교통 정보, 조류 이동 경로 등을 감안해 조류 인플루엔자(AI) 확산 경로를 추정한다. 오픈소스 프로그램이라 사용자들이 자신의 지역에 맞게 기능을 계속 추가할 수도 있다. 현재 240여 개 지역용 플러그인(부가 프로그램)이 추가됐다.

질병통제예방센터(CDC) 등 미국 방역기관은 단계별 감염병 대응 전략을 세울 때 이런 프로그램들을 이용한다. 안인성 한국과학기술정보연구원(KISTI) 생명의료예측기술 연구실장은 “특정 지역의 학교 휴업 여부 등 정책적 판단을 내릴 때 빅데이터를 이용한 시뮬레이션 결과를 반영한다”고 말했다.
현재 걷잡을 수 없게 번지고 있는 메르스를 막는 데 이런 수학적 모델을 사용할 수는 없을까. 감염병 확산과 같이 무질서해 보이는 현상 뒤에 숨은 규칙을 분석하는 ‘복잡계(Complex System) 네트워크’ 전문가인 정하웅 KAIST 물리학과 석좌교수는 “현재로선 힘들다”고 답했다.
복잡계 네트워크 분석의 핵심은 허브를 찾는 것이다. GLEaM 같은 프로그램들은 각지의 공항을 허브로 놓고 주변 연결망을 분석한다. 한데 현재 메르스는 지역이 아니라 병원 감염을 통해 확산되고 있다. 평소 다른 사람과 접촉이 많았던 사람이 아니라 병원에 입원한 특정 환자가 ‘감염 허브’ 역할을 하고 있다. “워낙 특수한 상황이라 일반화하기가 힘들다. 모델을 만들 수는 있지만 에러가 많아 큰 의미가 없다”는 게 정 교수 얘기다.
분석에 필요한 ‘가공된’ 데이터가 부족한 것도 문제다. 감염병 확산을 예측하려면 상세한 인구 데이터와 이들의 이동 정보가 필요하다. 정보통신(IT) 강국인 한국은 외국보다 이런 빅데이터가 잘 구축돼 있다. 인구 센서스나 교통카드 이용 정보, 건강보험관리공단·건강보험심사평가원의 병원 정보 등이다. 하지만 이들의 활용도는 오히려 외국보다 낮은 편이다. 안인성 KISTI 연구실장은 “각각의 데이터가 생산 기관 안에 갇혀 있다. 자료 형식도 제각각이다. 이를 가공해 과학자들이 원하는 매개 변수(파라미터)를 뽑아줘야 국내 실정에 맞는 예측 모델을 만들 수 있다”고 말했다. 빅데이터가 부처 간 ‘칸막이’에 막혀 있다는 것이다.
정부는 지난해 사회문제 해결형 과제 중 하나로 ‘감염병 조기 감시 및 대응 기반 확보’ 사업을 선정했다. 5년간 총 480억원을 들여 미래창조과학부·보건복지부·농림축산식품부 등 여러 부처가 함께 연구개발(R&D)을 하기로 했다. 하지만 복지부만 20억원을 받고 나머지 부처는 예산을 못 받았다.
'축산이슈 > 시장상황' 카테고리의 다른 글
| 미 FDA, 가공식품서 ‘트랜스지방 퇴출’ 최종 결정 (0) | 2015.06.17 |
|---|---|
| (미래) HMD - 가상현실, 신소재 - 우주시대 (0) | 2015.06.17 |
| 4대강 사업 덕분이다 vs. 전세계 지하수 고갈 직전 (0) | 2015.06.16 |
| 매년 반복되는 기상이변은 이변이 아니다 (0) | 2015.06.12 |
| 하림, 글로벌 곡물 메이저·에너지사업 도약 (0) | 2015.06.11 |



댓글